
Über die Success Stories und Use Cases
Damit Sie sich ein besseres Bild von unserer Arbeit machen können, haben wir mit der Hilfe der NFDI-Konsortien eine Sammlung von Success Stories und Use Cases erstellt. Dazu gehören unter anderem Helpdesks, Forschungsdatenmanagement-Services aller Art und audiovisuelle Angebote.
Die Seite wird regelmäßig aktualisiert.
Geistes- und Sozialwissenschaften
Der interaktive virtuelle Assistent von BERD@NFDI hilft beim Datenschutz
|
Interaktiver Virtueller Assistent (iVa) BERD@NFDI hat einen Interaktiven Virtuellen Assistenten (iVa) entwickelt, der Benutzern dabei hilft, die Komplexitäten der Datenschutzbestimmungen insbesondere hinsichtlich rechtlicher Fragen zu verstehen und die rechtlichen Optionen für die Verwendung von Daten in ihren Projekten erkunden. Speziell ausgerichtet für die Bereiche Wirtschaft, Wissenschaft und Sozialwissenschaften, führt iVA die Benutzer durch einen Entscheidungsbaum mit konkreten Fragen, kurzen Beispielen und präzisen Definitionen; anstelle von reiner Theorie bietet es praktische Einblicke. iVA besteht aus verschiedenen Modulen, von denen jedes eine bestimmte Datenschutzfrage behandelt. Wählen Sie ein Modul und probieren Sie es aus. |
Das Forum4MICA von KonsortSWD bündelt Wissen über relevante Forschungsdateninfrastrukturen

Einzigartige Austauschplattform, die Expertise zu Forschungsdaten und Forschungsdatenmanagement niedrigschwellig bündelt
Das Forum4MICA – Making Information Commonly Available –ermöglicht den Austausch zwischen Forschenden als Datennutzenden und Forschungsdatenzentren (FDZ) als Datenanbietern. Bereits in den ersten Monaten haben sich 15 der 41 FDZ als Partner verpflichtet und knapp 400 Personen als aktive Forumsteilnehmende registriert, Tendenz steigend.
Forschende können im Forum (a) ihre individuellen Fragen stellen, (b) eigene Erfahrungen und Lösungsvorschläge einbringen sowie (c) systematisch nach Informationen suchen. Angesichts der Größe und Komplexität der Datenbestände im multidisziplinären Feld von KonsortSWD ist mit dem Forum ein einfacher, nachhaltiger und niedrigschwelliger Zugangsweg zu Wissen über relevante Forschungsdateninfrastrukturen für die Scientific Community entstanden.
Das QualidataNet von KonsortSWD erhöhen die Sicht- und Auffindbarkeit von sozialwissenschaftlichen Daten
Erstmalig übergreifendes Angebot für bedeutenden Teil der Forschenden in den Sozialwissenschaften
QualidataNet ist ein Netzwerk von Forschungsdatenzentren, Archiven und Repositorien mit Fokus auf qualitativen Forschungsdaten. Als „single point of entry“ bündelt QualidataNet Informationen über Forschungsdaten und Angebote unterschiedlicher Archivierungsinfrastrukturen.
Forschende können im Portal Daten und Archivierungspartner finden und bekommen Informationen darüber, wie sie Daten nutzen und managen können.
Forschungsdatenzentren, Archive und Repositorien erhöhen die Sicht- und Auffindbarkeit ihrer Daten und vernetzen sich mit anderen Anbietern.
Das Portal ist Ende Dezember 2023 online gegangen. Der Funktionsumfang wird beständig erweitert.
Der Legal Helpdesk von NFDI4Culture hilft bei rechtlichen Fragen im Forschungsdatenmanagement

Eine kompetente Anlaufstelle: Der Legal Helpdesk von NFDI4Culture beantwortet Fragen zum Urheberrecht und Datenschutz
„Was bedeuten die Änderungen im Urheberrecht für unsere digitalen Sammlungen?“, „Was sollten wir für eine wirksame Einwilligung zur Datenverarbeitung beachten?“Als Teil des NFDI4Culture Helpdesk bietet der beim Leibniz-Institut für Informationsinfrastruktur (FIZ) Karlsruhe angesiedelte Legal Helpdesk ein juristisch kompetentes Gesprächs-und Informationsangebot für diese Fragen. Das Themenspektrum reicht von Datenschutz und Urheberrecht bis hin zu ethischen Aspekten im Forschungsdatenmangement.
Der individuelle, direkte Austausch steht Forschenden, Kulturschaffenden, Kulturerbe-Institutionen und Forschungsprojekten offen. Von der einfachen Verständnisfrage über den Austausch zu Datennutzungsplänen bis zu Strategien des Rechtemanagements hat sich der Legal Helpdesk als verlässlicher, gern genutzter Service etabliert.
Weitere Success Stories von NFDI4Culture auf dem NFDI4Culture Portal!
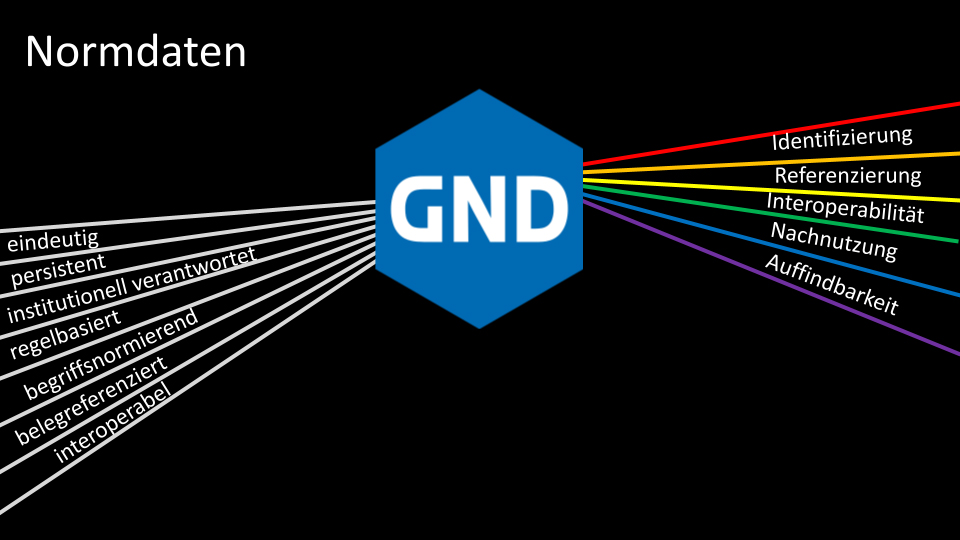
Mit der Gemeinsamen Normdatei (GND) wertet Text+ geistes- und kulturwissenschaftliche Daten auf

Normdaten in geistes-und kulturwissenschaftlichen Forschungsdaten
In Text+, dem NFDI-Konsortium für sprach- und textbasierte Forschungsdaten, arbeiten die Deutsche Nationalbibliothek und die Niedersächsische Staats- und Universitätsbibliothek Göttingen mit weiteren Partnern zusammen, um die Erschließung geistes- und kulturwissenschaftlicher Forschungsdaten mit Normdaten der Gemeinsamen Normdatei (GND) auszubauen und bisher unerschlossene Datenbestände mit Normdaten aufzuwerten. Unter Normdaten versteht man solche Forschungsdaten, welche unabhängig von Faktoren wie Schreibweise eindeutig z.B. einer Person zugeordnet werden können etwa mithilfe einer Identifikationsnummer. Davon profitieren Forschung und Öffentlichkeit gleichermaßen, denn als Normdaten ausgewiesene Entitäten in Forschungsdaten (Personen, Werke, Geografika, Sachbegriffe etc.) sind eindeutig referenzierbar und interoperabel, sie bieten bei der Datenrecherche eindeutige Sucheinstiege und können in ihrer Verwendung als kontrolliertes Vokabular in unterschiedlichen Informationsressourcen die Entwicklung des Semantic Web vorantreiben.
Archive und Digital History im Dialog: 4Memory Summer School Reihe startet erfolgreich unter dem Motto „Linking Data|Linking Communities”
![]()
Archive und Digital History im Dialog: 4Memory Summer School Reihe startet erfolgreich unter dem Motto „Linking Data|Linking Communities”
Im Herzen der Stuttgarter Innenstadt kamen vom 24. bis 26. September 2024 rund 30 Expert*innen aus Archivwesen und Digital History auf Einladung des Landesarchiv Baden-Württemberg zur ersten 4Memory Summer School zusammen. Gemäß dem Motto der Veranstaltungsreihe „Linking Data|Linking Communities“ stand die gemeinsame Diskussion über an der Schnittstelle zwischen beiden Communitys angesiedelte digitale Methoden und Use Cases im Fokus. Mit Vertreter*innen aus Forschung, Gedächtniseinrichtungen und Forschungsinfrastrukturen versammelte die Veranstaltung sowohl Produzierende als auch Nutzende historischer Daten. Die Diskussionen konzentrierten sich auf die unterschiedlichen Anforderungen an historische Forschungsdaten und gemeinsame Perspektiven auf die Methoden und Werkzeuge der Digital Humanities. Die Gastgebenden hatten Universitätslehrende und Repräsentant*innen aus den Ausbildungseinrichtungen für Archive hinzugezogen, was ein gemeinsames Gespräch über die Vermittlung von Data Literacy ermöglichte. Für die Gestaltung einer gemeinsamen Datenkultur für die in NFDI4Memory versammelten historisch arbeitenden Geisteswissenschaften markiert die Summer School einen wichtigen ersten Schritt. Die nächste Summer School wird 2025 am Herder-Institut für historische Ostmitteleuropaforschung – Institut der Leibniz-Gemeinschaft in Marburg stattfinden. Das Format bietet damit weiterhin eine wichtige Plattform für den Austausch und die Zusammenarbeit von Angehörigen der verschiedenen Communitys und kann an wertvolle Impulse der Auftaktveranstaltung anknüpfen.
Humanities@NFDI: Gemeinsam für nachhaltige Forschungsdaten
Fächerübergreifende Kooperation für den Erhalt des kulturellen Erbes
In den Geistes- und Kulturwissenschaften entstehen unter anderem in Forschungseinrichtungen, Museen, Bibliotheken, Archiven und Theatern täglich neue Daten. Dazu gehören beispielsweise sensorische Vermessungen von archäologischen Fundstätten, digitale Repräsentationen von Notenblättern, Bleiisotopenanalysen, 3D-Modelle kulturhistorischer Denkmäler, Aufnahmen von Bühnenaufführungen, archivische Überlieferung aus Verwaltung und Gesellschaft wie E-Akten oder Soziale Medien, Retrodigitalisate von Handschriften und Urkunden, Korpora und digitalisierte Texte oder lexikalische und linguistische Ressourcen. Um die Qualität und langfristige Verfügbarkeit dieser Daten zu sichern, haben sich seit einer Workshopserie 2018 die Konsortien NFDI4Culture, NFDI4Memory, NFDI4Objects und Text+ als Humanities@NFDI mit einem Memorandum of Understanding bereits 2020 transkonsortial zusammengeschlossen.
Von Standards bis Workshops: Synergien in der Praxis
Interdisziplinäre Forschung steht häufig vor dem Problem der Vergleichbarkeit: Um Daten fachübergreifend auffindbar, zugänglich, interoperabel und wiederverwendbar zu machen, müssen sowohl Referenzierungen als auch Metadaten interdisziplinär abgestimmt werden. Dafür setzt sich die AG zur Entwicklung einer gemeinsamen Ontologie ein. Weitere Beispiele sind unter anderem das gemeinsame Register für historische und objektbezogene Vokabulare (R:hovono), die AG Minimaldatensatz, die Zusammenarbeit an den DFG-Praxisregeln „Digitalisierung“ oder die Social-Media-Reihe Show & Tell. Diese Formate schaffen nicht nur Standards, sie fördern auch den Wissenstransfer und die Vernetzung innerhalb der Community und tragen zu einem Kulturwandel bei.
Ingenieurwissenschaften
Die AI Ethics Videoserie von NFDI4DataScience klärt ethische Fragen zu künstlicher Intelligenz
![]()
AI Ethics Video Series
NFDI4DS entwickelt Schulungsmaterialien und organisiert Veranstaltungen, die sich mit Prozessen und Methoden der Datenwissenschaft und KI befassen.
In diesem Rahmen wurde eine Videoserie über ethische Aspekte in der KI produziert. Zu diesem Zweck wurde ein Lehrplan entwickelt und ein Fragebogen für die Serie erstellt. Jede Folge beleuchtet einen bestimmten Aspekt und interviewt bekannte Experten auf dem Gebiet. Die Zielgruppe sind Praktiker aus der Datenwissenschaft und der KI-Gemeinschaft.
Die zehn Episoden der Videoserie sind auf YouTube verfügbar.
Der Open Research Knowledge Graph von NFDI4DataScience erleichtert das Finden von Forschungsarbeiten
![]()
Open Research Knowledge Graph
Akademisches Wissen. Vergleichbar.
Die Kernidee von NFDI4DS ist es, die Transparenz, Reproduzierbarkeit und Fairness von Data Science- und KI-Projekten zu erhöhen, indem alle digitalen Artefakte verfügbar gemacht, miteinander vernetzt und innovative Werkzeuge und Dienste angeboten werden.
Der Open Research Knowledge Graph (ORKG) ist eine Schlüsselkomponente für diese Vision. Er zielt darauf ab, Forschungsarbeiten auf strukturierte Weise zu beschreiben. Mit dem ORKG sind Arbeiten leichter zu finden und zu vergleichen.
• ORKG: https://orkg.org/
• Stories von Wissenschaftlern: https://orkg.org/about/36/ORKG_Stories
• Kurzer Überblick für Anfänger: https://orkg.org/about/14/Get_started
Das Meta-Portal von NFDI4DataScience verknüpft verschiedene Metadaten
![]()
NFDI Meta-Portal
Die Kernidee von NFDI4DS ist es, die Transparenz, Reproduzierbarkeit und Fairness von Data Science- und KI-Projekten zu erhöhen, indem alle digitalen Artefakte verfügbar gemacht, miteinander verknüpft und innovative Tools und Dienste angeboten werden.
Als eine Schlüsselkomponente dieser Vision wird ein Meta-Portal bereitgestellt, das eine Vielzahl unterschiedlicher Ressourcen wie Publikationen (z.B. von Zenodo), Daten (z.B. von CKAN, DSpace, Dataverse, Invenio) und Code (z.B. von GitHub und GitLab) integrieren soll.
Das Meta-Portal wird eine Reihe von verschiedenen Werkzeugen bereitstellen, darunter eines zur Bewertung der Metadatenqualität.
Das Meta-Portal basiert auf piveau, einem Datenmanagement-Ökosystem für den öffentlichen Sektor.
Meta-Portal: meta4ds.fokus.fraunhofer.de
Der NFDI Science Slam - organisiert von NFDI4DataScience - vereint Unterhaltung mit Forschungsdatenmanagement-Themen
![]()
NFDI Science Slam
NFDI4DS organisiert verschiedene Veranstaltungen, die der breiten Öffentlichkeit Forschungsdateninfrastrukturen näher bringen.
In Zusammenarbeit mit der Berlin Science Week veranstaltet NFDI4DS jedes Jahr einen Science Slam. Die Idee ist, die Arbeit der NFDI und ihrer Konsortien auf verständliche und unterhaltsame Weise zu erklären.
Bislang hat NFDI4DS 3 Ausgaben in den Jahren 2021, 2022 und 2023 mit insgesamt 14 Slams aus 11 Konsortien erfolgreich durchgeführt. An der Veranstaltung nahmen bis zu 80 Personen persönlich und bis zu 200 Personen virtuell teil.
Alle Slams sind auf Youtube verfügbar.
Coscine von NFDI4Ing fördert Forschungsdatenspeicherung konsortienübergreifend
![]()
Coscine
Die Forschungsdatenplattform Coscine kombiniert eine Implementierung der FAIR-Prinzipien mit föderierten, industrietauglichen und skalierbaren Datenspeichersystemen und bietet Bereitstellungs- und Zugriffsmanagementprozesse.
Coscine wird in NFDI4Ing kontinuierlich weiterentwickelt, um die Bedürfnissen von Ingenieurwissenschaftler:innen anzudecken. Für 42 nordrhein-westfälische Hochschulen wird Coscine.nrw bereits als föderierter Dienst angeboten, der FAIR-Datenmanagement für eine breite Gemeinschaft von Forschern bereitstellt.
2023 ist Coscine erfolgreich aus der Pilotphase in den Regelbetrieb übergegangen und bedient nun über 1500 interdisziplinäre Nutzer aus 138 Hochschulen und anderen Forschungsorganisationen aus der Research Organization Registry. Im Bereich der Ingenieurwissenschaften unterstützt Coscine bereits über 1000 Projekte. Die niedrigschwellige Zugangsverwaltung der Plattform auf der Basis von DFN AAI und ORCID ermöglicht eine breite Zusammenarbeit auch über den akademischen Bereich hinaus.
Als zentraler Dienst fördert Coscine die Zusammenarbeit innerhalb und zwischen NFDI-Konsortien. Coscine wird bereits intensiv in NFDI4Ing und NFDI-MatWerk genutzt. In NFDI4Chem und NFDI4Microbiota wird Coscine in einzelnen Arbeitsgruppen evaluiert, was das große Potenzial für verbundübergreifende Synergien zeigt.
Der Data Collections Explorer von NFDI4Ing erleichtert den Zugang zu Datensammlungen
Data Collections Explorer
Der Data Collections Explorer (DCE) ist ein einfach zu bedienendes Informationssystem für die Ingenieurwissenschaften. Er bietet einen schnellen Überblick über fachspezifische Repositorien, Archive und Datenbanken sowie über Datensätze, die außerhalb dieser etablierten Infrastruktur veröffentlicht wurden.
Der Data Collections Explorer bündelt wichtige Informationen wie Open-Access-Politik, API-Zugang, Publikationskosten und Größenbeschränkungen von Datensätzen in einer übersichtlichen Darstellung. Dies hilft Wissenschaftlern, die entweder ihre Forschungsdaten veröffentlichen wollen oder nach Daten suchen, um ihre Forschung voranzutreiben.
Seit dem Start im März 2022 hat der Data Collections Explorer in NFDI4Ing schnell an Zugkraft gewonnen. Ausschlaggebend waren dabei die vielen Beiträge von Wissenschaftler:innen auch außerhalb der Ingenieurwissenschaften. Der Data Collections Explorer stößt auch bei anderen Konsortien und Initiativen außerhalb der NFDI auf Interesse. Im nächsten Schritt arbeitet NFDI4Ing daran, die materialwissenschaftliche und ingenieurwissenschaftliche Gemeinschaft innerhalb von NFDI-MatWerk einzubinden. Darüber hinaus plant das Konsortium die Einrichtung eines Wissensgraphen, der unter anderem eine einfachere Integration in bestehende und künftige Projekte ermöglichen wird.
Das Education Gitlab von NFDI4Ing bietet Bildungsmöglichkeiten im Bereich Forschungsdatenmanagement
![]()
Education Gitlab
Das NFDI4Ing Education Gitlab ist eine Plattform für die Bereitstellung von und die Zusammenarbeit an offenen Bildungsressourcen (OER) im Bereich des Forschungsdatenmanagements (FDM). Es ist ein interdisziplinäres Projekt, das im NFDI4Ing-Konsortium angesiedelt ist, aber von jedem mit einem GitLab-Konto genutzt und erweitert werden kann. Es ist eine wertvolle Ressource für jeden, der sich für RDM interessiert oder sein Wissen dazu weitergeben möchte.
Auf den Education Pages bietet NFDI4Ing Schulungen zum Forschungsdatenmanagement an, die sich auf Anwendungen im Ingenieurwesen konzentrieren. Durch die Verwendung von ingenieurspezifischen Anwendungsfällen, Beispielen und Merkmalen sind die Schulungen speziell auf die Bedürfnisse von Ingenieuren zugeschnitten. Um die Inhalte interaktiv zu gestalten, wurden Elemente wie Videos und Quizfragen integriert. Die Schulungen decken den gesamten Lebenszyklus von Daten ab und behandeln Themen wie Datenmanagementpläne und Datenwiederverwendung sowie übergreifende Felder wie Metadaten, Dateiformate, Softwareentwicklung und Lizenzen.
Die Schulungen und die dazugehörige Plattform wurden unter Berücksichtigung von Aspekten offener Bildungsressourcen (OERs) erstellt: Die Trainings sind offen und ohne Registrierung verfügbar und stehen unter der Lizenz CC BY 4.0. Um offene und etablierte Plattformen und Formate zu nutzen, sind die Trainings auf GitLab-Seiten als Plattform, Markdown- und HTML-Dateien für den Inhalt und H5P für interaktive Elemente implementiert. Neben der Kuratierung durch das NFDI4Ing Training & Education Team sind die Nutzer eingeladen, ihr Feedback über das GitLabs Issue System zu teilen und so den Service kontinuierlich zu verbessern.
Weitere Informationen über RDM-Schulungen für die Ingenieurwissenschaften finden Sie hier.
Mit dem Attended Cloud Housing ermöglicht NFDI4Ing die Speicherung großer Daten
![]()
Attended Cloud Housing
Daten aus High-Performance Computing (HPC) und High-Performance Measurements sind häufig in persönlichen (Projekt-) Accounts bei Rechenzentren gespeichert und aufgrund ihrer Größe immobil. Der Zugriff auf die Daten oder die Weiternutzung waren bisher nicht ohne expliziten Antrag beim Rechenzentrum möglich, da Daten auf Großrechenanlagen bisher ausschließlich den Erzeugern und Projektbeteiligten zugänglich sind.
Mit der Einrichtung eines Cloud-Serversystems am Leibniz-Rechenzentrum (LRZ) und dem Gauss Centre for Supercomputing ist eine Plattform geschaffen worden, die den Aspekt der ‚accessibility‘ der FAIR-Prinzipien praktisch umsetzt. Mit Cloud-Serversystemen wird die Möglichkeit geschaffen, am Leibniz-Rechenzentrum (LRZ) erzeugte Forschungsdaten für Externe nutzbar zu machen. Der Zugang kann dabei individuell per virtueller Maschine oder per Mikroservice eingestellt werden. Durch die direkte Einbindung in die Datenspeicherinfrastruktur des Rechenzentrums, kann sowohl auf “heiße”, als auch “kalte” HPC-Forschungsdaten zugegriffen werden. Eine Auswertung der Daten auf der virtuellen Maschine ist dabei möglich. Die riesigen, immobilen Datenmengen sind dabei direkt über die Cloud zugänglich und somit für eine Nachnutzung erreichbar. Dabei bietet das Cloud-System die folgenden Nutzungsmöglichkeiten:
- Bereitstellung exklusiver Nutzungsrechte innerhalb einer professionell verwalteten Compute Cloud
- Ausführung virtueller Maschinen auf der Cloud zur Auswertung der Daten vor Ort
- Schnelle Anbindung an bestehende Systeme zur Datenspeicherung des LRZ
Der Scientific Knowledge Graph Tex hilft Forscher:innen ihre Forschungsinformationen zugänglich zu machen
![]()
Scientific Knowledge Graph TeX
Scientific Knowledge Graph TeX (SciKGTeX) ist ein LaTeX-Paket, mit dem Forschungsbeiträge direkt im LaTeX-Quellcode annotiert werden können. Mit SciKGTeX können Autoren ihre Publikationen mit strukturierten, maschinenverarbeitbaren und FAIRen wissenschaftlichen Informationen anreichern, die sie ihren Lesern mitteilen möchten. Diese Informationen werden in die XMP-Metadaten des PDF-Dokuments eingebettet, wo sie von jedem, der das PDF-Dokument erhält, abgerufen werden können. Das bedeutet, dass die Informationen während der gesamten Lebensdauer des Artefakts erhalten bleiben. Auf diese Weise verbessert die Verwendung von SciKGTeX die elektronische Archivierung wissenschaftlicher Informationen und fördert ihre Auffindbarkeit und (Wieder-)Verwendung, beispielsweise in Suchmaschinen und Empfehlungssystemen.
SciKGTeX ist bereits im Einsatz. Der Open Research Knowledge Graph (ORKG), eine zentrale Infrastruktur in NFDI4Ing, NFDI4DataScience und NFDI4Energy, bietet bereits eine Upload-Funktion für SciKGTeX-annotierte PDFs an, die es Autoren ermöglicht, ihre annotierten Forschungsbeiträge schnell und einfach in den ORKG einzustellen. Die Zeitschrift ing.grid nutzt SciKGTeX als integriertes Paket in ihrer LaTeX-Vorlage für Artikel. Für die 30th International Working Conference on Requirement Engineering: Foundation for Software Quality wird im Rahmen einer Open-Science-Initiative allen Autoren empfohlen, ihre eingereichten Artikel mit SciKGTeX zu annotieren.
Auf der ACM/IEEE Joint Conference on Digital Libraries 2023 wurde die Publikation zu SciKGTeX [1] mit dem Vannevar Bush Best Paper Award (dotiert mit 1000 Dollar) ausgezeichnet.
Weitere Informationen über das Tool und sein Projekt finden Sie unter: https://github.com/Christof93/SciKGTeX
Jards von NFDI4Ing weitet den Speicherplatz für Forschungsdaten aus
Speicherplatz ist teuer, und die Nachfrage unter Forschenden groß. Die meisten bestehenden Systeme zur Verteilung von Speicherplatz sind ad-hoc, erfordern (interne) Geldtransfers, skalieren nicht auf institutioneller oder sogar nationaler Ebene und verursachen im Allgemeinen einen gewissen formalen Overhead. In NFDI4Ing wollen wir die Beantragung und Allokation wissenschaftlicher IT-Ressourcen vereinheitlichen und den Verwaltungsprozess vereinfachen.
Ausgehend von unserer bestehenden Datenverwaltungsplattform Coscine haben wir Jards, ein Tool, das bereits in vielen Rechenzentren zur Verwaltung von Anträgen auf Rechenzeit eingesetzt wird, so angepasst, dass es auch Anträge auf Speicherplatz bearbeiten kann. Jards ermöglicht dann eine wissenschaftlich geleitete Prüfung des Antrags und der Arbeits- und Datenflüsse und gewährleistet so einen nachhaltigen Umgang mit den Forschungsdaten und Metadaten. Jards bietet ein Antragsverfahren, das Vorschläge auf der Grundlage des wissenschaftlichen Werts und der Umsetzung der FAIR-Grundsätze bewertet. Es ist als föderierter Dienst für 42 Hochschulen in Nordrhein-Westfalen und die NFDI-Konsortien, an denen sie beteiligt sind, verfügbar. Sie nutzen es unter anderem, um den Verteilungsprozess für Speicherressourcen, die vom DataStorage.nrw-Konsortium bereitgestellt werden, zu koordinieren.
Der Research Data Management Organiser von NFDI4Ing verwaltet große Datenmengen
![]()
Durch stetig steigende Datenmengen und Kooperationen im Wissenschaftsbetrieb wird es immer wichtiger, die Datenhaltung für ein Projekt vorab zu planen. NFDI4Ing stellt für die Ingenieurwissenschaften einen Assistenten zur Verfügung, der bei der Planung des Datenmanagements unterstützt. Dadurch wird sichergestellt, dass Daten besser aufbereitet und somit für weitere Forschung einfacher nachgenutzt werden können.
Lebenswissenschaften
Das Data Steward Service Center von FAIRagro kümmert sich um Fragen aus der Wissenschaft
:
![]()
Data Steward Service Center
„Das DSSC unseres jungen Konsortiums hat sich innerhalb weniger Wochen nach Projektstart im März 2023 erfolgreich formiert und zeichnet sich durch eine Kombination aus Teamwork und zugleich selbstständiger Aufgabenbearbeitung aus. Wir sind fünf Data Stewards und ein Koordinator, die sich diversen Anfragen aus der nationalen und internationalen Agrosystem-Community widmen. Jeder unserer Data Stewards ist Expert:in eines bestimmten Bereichs der Agrosystemforschung. Dazu gehören Geodaten, Daten von Pflanzeninventuren, landwirtschaftliche Langzeitversuche und genetische Daten. Darüber hinaus haben wir als erstes Konsortium auch eine ausgebildete Volljuristin als Data Steward für Recht und Ethik. Dadurch sind wir in der Lage, die Fragen der Community direkt selbst kompetent zu beantworten, sodass kein Outsourcing betrieben werden muss. Dies macht unseren Service agil und effizient. Konkret erreichen uns Anfragen über die zentrale E-Mail-Adresse „dataservice@fairagro.net“. Diese werden dann von unserem Koordinator in Tickets umgewandelt und entsprechend der Expertise an eine:n oder mehrere Data Stewards zugeteilt, die diese Tickets dann selbstständig bearbeiten und verwalten. So konnten wir uns zum Jahresende 2023 bereits 27 Community-Anfragen widmen. Durch die Größe und Diversität unseres Teams tragen wir auch erfolgreich zu der Vernetzung mit anderen Helpdesks (sowohl NFDI als auch lokal) sowie mit den Landesinitiativen bei.“ [Autorin: Lea Singson, Data Steward im DSSC]
Leitende Einrichtung des DSSC ist das Leibniz Zentrum für Agrarlandschaftsforschung (ZALF) mit eigenem Repositorium (BonaRes Repository).
NFDI4Health erarbeitet umfangreiche Übersicht über Datenanonymisierungstools
![]()
Übersicht Datenanonymisierungstools
NFDI4Health entwickelte ein Tool für die Anonymisierung tabellarischer Daten, um die Auswahl geeigneter Werkzeuge für Datenanalysten zu erleichtern. Die Anonymisierung medizinischer Datensätze stellt einen wichtigen Schritt von Data Sharing-Prozessen dar und hilft, die Privatheit der Betroffenen zu schützen. Valide Anonymisierungen müssen auf statistischen Modellen basieren, um Re-Identifizierungsrisiken zu messen und zu verringern. Hierbei ist es ratsam, bereits bestehende und robuste Implementierungen einzusetzen. NFDI4Health liefert mit seiner Arbeit über Datenanonymisierungstools einen Überblick über die verfügbaren Open Source Werkzeuge zur Anonymisierung und analysiert deren Stärken und Schwächen.
Zur Publikation: https://doi.org/10.1093/bib/bbac440
Naturwissenschaften
NOMAD von FAIRmat schafft eine digitale Infrastruktur in den Materialwissenschaften

NOMAD
NOMAD ist eine digitale Infrastruktur für die riesigen Datenmengen aus dem weiten Feld der Materialwissenschaften. Das Konsortium FAIRmat hat dazu die ursprüngliche Sammlung von Simulationsergebnissen in viele Richtungen weiterentwickelt. Dies betrifft nicht nur Berechnungen angeregter Zustände mittels Vielteilchentheorien und klassischer Molekulardynamik; NOMAD ist auch zu einer Plattform für Probenherstellung, verschiedenste experimentelle Methoden und einer Vielzahl von Anwendungen gewachsen. FAIRmat hat hierfür (Meta-)Datenmodelle und grafische Oberflächen entwickelt, um die Fülle heterogener Daten zu verarbeiten und zu beschreiben. Heute umfasst NOMAD 13 Millionen Einträge zu mehr als 3 Millionen Materialien.
Mit den interaktiven NOMAD Apps lassen sich die domänenspezifischen Daten im Detail erkunden und auch miteinander vergleichen. Diese Apps bieten individuell gestaltbare Benutzeroberflächen zur Datenvisualisierung. Zum Beispiel beinhaltet die Solar-Cell App über 40 000 Datensätze von Bauelementen aus dem Perovskite Database Project. Mehr als 17 000 Berechnungen enthält unsere Datensammlung zu Metal-Organic Frameworks, die derzeit um Information zu deren Synthese erweitert. In Kürze werden weitere Apps verfügbar sein, die von der heterogenen Katalyse bis zur Batterieforschung reichen.
Mit NOMAD Oasis bringt FAIRmat unsere Dateninfrastruktur auch in individuelle Labore. NOMAD Oasis ermöglicht es Forschenden aus verschiedenen Fachbereichen, die NOMAD-Software an ihre individuellen Bedürfnisse anzupassen. Besuchen Sie unsere Website unter: https://nomad-lab.eu.
MaRDI organisiert Universitätsvorlesungen zu Forschungsdatenmanagement in der Mathematik
![]()
Universitätsvorlesung für mathematisches Forschungsdaten-Management
Eine im Sommer 2021 durchgeführte Umfrage an deutschen Mathematikfakultäten ergab, dass die Lehrenden das Bewusstsein und die Kenntnisse ihrer Studierenden in Bezug auf gute wissenschaftliche Praxis, Autorenschaft, die FAIR-Prinzipien und Forschungssoftware als zu gering einschätzen. Es handelt sich dabei um klassische Themen des Forschungsdatenmanagements (FDM). Motiviert durch diesen Bedarf und durch erfolgreiche, fächerübergreifende FDM-Kurse an den Universitäten Bielefeld und Leipzig, fanden im Sommersemester 2023 in Leipzig sechs Vorlesungen zum Forschungsdatenmanagement für Mathematiker*innen statt. Nach Kenntnis der Dozentin war dies der erste Kurs dieser Art. Die große Gruppe der Teilnehmenden umfasste eine große Bandbreite an Erfahrungsstufen, darunter Studierende, Doktoranden, Postdocs und MaRDI-Mitarbeitende. Lebhafte Diskussionen drehten sich um die Besonderheiten und allgemeine Probleme mathematischer Forschungsdaten, und die Schwierigkeiten bei der Entscheidung über geeignete Metadaten für mathematische Ergebnisse, die wissenschaftliche Methode, gute wissenschaftliche Praxis und die Art und Weise, wie man Mathematik schreibt, zitiert und dokumentiert.
Die Rückmeldungen zu diesem Kurs waren sehr gut. Die Studierenden schätzten die interaktive Atmosphäre, die Zeit, die für Fragen zur Verfügung stand, und den informellen Charakter des Unterrichts. Ein eintägiger Mathe-FDM-Kurs mit Beteiligung von Professor*innen in Magdeburg im November baute auf dieser ersten erfolgreichen Veranstaltung auf und behandelte neben einführenden Themen auch Fragen der Reproduzierbarkeit und Repositorien. Vorlesungsskripte für beide Veranstaltungen sind in Arbeit. Sie werden im nächsten Sommersemester öffentlich zugänglich gemacht, damit sie von allen, die sich für das Thema Mathematik-FDM interessieren, frei verwendet werden können.
RDM4Lab von NFDI4Cat hilft, Forschungsdaten zu verwalten
![]()
Laborpraktikum Technische Chemie
Die Fakultät für Chemie der TU München bietet für Studierende der Chemie und des Chemieingenieurwesens das Laborpraktikum „Technische Chemie“ an. Das Laborpraktikum umfasst katalysebezogene Experimente, die von den Studenten durchgeführt werden. In der Regel sind etwa 100 Studenten pro Semester eingeschrieben, und jeder Student führt mindestens acht verschiedene Experimente durch. Dies führt dazu, dass jedes Jahr mehr als 800 Experimente und Berichte erstellt werden, die von den Betreuern (in der Regel Doktoranden und Postdocs) bewertet werden. Wir haben ein Tool für die Verwaltung von Forschungsdaten, „RDM4Lab“, entwickelt, um die in diesem Laborkurs erzeugten Daten systematisch und unter Einhaltung der FAIR-Grundsätze(Findable, Accessible, Interoperable, and Reusable) zu speichern. Das Tool beinhaltet auch Funktionen wie die Visualisierung der aktuellen und historischen Daten und die automatische Datenanalyse, um den Betreuern die Bewertung der Berichte zu erleichtern
LARA von NFDI4Cat revolutioniert Forschungsdatenmanagement
LARASuite
Die LARAsuite ist ein quelloffenes Forschungsdatenmanagement System der nächsten Generation: es implementiert einen radikal automatisierbaren Ansatz, so dass Eingaben von Daten und Metadaten auf das allernotwendigste reduziert werden. Dazu verwendet es open-source Laborkommunikationsprotokolle, offene Daten- und Metadaten Standards und eine semantische, Ontologie-basierte Repräsentation der Daten.
Daten können zwischen verschiedenen LARA-Instanzen ausgetauscht und mit (Inter-)nationalen Repositorien synchronisiert werden. Abfragen können mittels SPARQL durchgeführt werden.
Die LARAsuite und viele Komponenten werden von einer internationalen Open-Source Community entwickelt. Es kann in sehr vielen naturwissenschaftlichen Bereichen eingesetzt werden.
Der Metadata Shaper von NFDI4Cat kreiert eine einheitliche Beschreibung von Forschungsdaten
Metadata Shaper
Um ein heterogenes Fachgebiet mit Metadaten beschreiben zu können, wird eine Sprache benötigt, die über die Grenzen der Domänen hinweg kommunizieren kann. Um dies zu ermöglichen, werden Metadatenstandards als einfaches und universelles Vokabular verwendet, um eine Schnittstelle zwischen Wissensdomänen zu schaffen. Diese können verschiedenste Forschungsbereiche umfassen, wie z. B. die Katalyseforschung, die Chemie oder die Verfahrenstechnik.
Eine Form eines solchen Metadatenstandards ist ein Metadaten-Framework, das nicht nur eine Standardisierung der Sprache darstellt, sondern auch eine einheitliche Datenbeschreibung in einer einfachen, aber aussagekräftigen Form ermöglicht. Dies ermöglicht eine einfachere Abbildung der Daten in Wissensgraphen und vereinfacht somit die Erstellung von Suchanfragen zu diesen Wissensgraphen.
Der Ontology Booster von NFDI4Cat macht Forschungsdaten einheitlich verständlich
Um Daten FAIR (auffindbar, zugänglich, interoperabel, wiederverwendbar) und für die weitere Forschung verfügbar zu machen, müssen wir eine Sprache, also ein semantisches Netz, entwickeln, das den Inhalt der Daten in einer für Menschen und Maschinen lesbaren Weise beschreiben kann. Ein wesentliches semantisches Werkzeug ist die Ontologie, die mit Hilfe einer mathematisch-logischen Sprache und der Annotation durch Verweise, Definitionen und Erklärungen ein Verständnis des Dateninhalts aufbaut. Da der Aufbau und die Erweiterung dieser Ontologien arbeitsintensiv und wissensintensiv ist, wird dies typischerweise nur von Domänen- und Semantik-Experten durchgeführt. In NFDI4Cat haben wir Werkzeuge entwickelt, die Domänenexperten bei der Entwicklung von Ontologien mit Natural Language Processing (NLP) unterstützen. In naher Zukunft wird es möglich sein, auch die zunehmend aufkommenden Large Language Models einzubeziehen. Vorschläge für neue Ontologieinhalte werden zusammen mit Verweisen auf bestehende Inhalte und die darauf basierende Informationsextraktion gut unterstützt.
Die Ontology Worldmap von NFDI4Cat fasst Forschungsdaten in nachvollziehbare Kategorien zusammen
Ontology World Map
Durch die Weiterentwicklung der Forschungsdateninfrastruktur FEI wird es immer wichtiger, sich mit Ontologien zu beschäftigen, die das logische Regelwerk für die Erstellung von Wissensgraphen darstellen und somit der standardisierten Vernetzung von (Meta-)Daten dienen. Im NFDI4Cat-Konsortium wurden die Ontologien, die die Themenbereiche der Katalyse abbilden, untersucht und auf ihre Verwendbarkeit in der NFDI bewertet.
Dies bietet einen systematischen Ansatz, um Ontologie-Metadaten zu sammeln, sie auf der Grundlage von Katalyse-Subdomänen zu klassifizieren und eine von Menschen lesbare Darstellung in einem GitHub-Repository zu erstellen. Darüber hinaus wird ein effizienter Vergleich und ein automatisiertes Mapping zwischen Ontologien ermöglicht, wobei der Schwerpunkt auf der Anpassungsfähigkeit an andere Wissensdomänen liegt. Das Repository soll sowohl als Anlaufstelle für neue Forscher als auch als Diskussionsforum für alle Forscher dienen, die an Ontologien (und Metadatenstandards) im Bereich der Katalyse und prozessbezogenen Wissenschaften interessiert sind.
NFDI4Earth und re3data kooperieren zur Verbesserung der Beschreibungen von Repositorien der Erdsystemwissenschaften
![]()
NFDI4Earth verbesserte die internationale Sichtbarkeit von Repositorien der Erdsystemwissenschaften (ESS) durch die Zusammenarbeit mit re3data und die Abstimmung von gemeinsamen Strategien zur Aktualisierung und Verbesserung der Metadaten von Repositorien. Beide Redaktionsteams unterstützten mehrere Repository-Anbieter bei der Erstellung, Aktualisierung oder Verbesserung ihrer re3data-Einträge. Neben neuen Datensätzen von behördlichen Partnern und Partnern aus der Forschung konnten bspw. auch persistente Identifikatoren für bestehende Einträge ergänzt werden, wie z. B. Research Organization Registry (ROR)-IDs.
NFDI4Earth stellt die kuratierten Informationen über seinen Knowledge Hub zur Verfügung und bietet auf dieser Weise der Community eine Datenquelle mit semantisch verknüpften Ressourcen an.
Durch die Bereitstellung eines etablierten, nachhaltigen Dienstes für kuratierte Repository-Informationen spielt re3data eine wesentliche Rolle in NFDI4Earth und darüber hinaus. Umgekehrt fungiert NFDI4Earth als essentielles Netzwerk, um die Erstellung und Kuratierung international relevanter erdsystemwissenschaftlicher Inhalte aktiv zu unterstützen.
Einbindung der Community zur digitalen Langzeitarchivierung durch NFDI4Earth
![]()
Die langfristige Sicherstellung der FAIRness relevanter (Forschungs-)Daten, über eine Aufbewahrungsfrist von 10 Jahren hinaus, ist für die Gestaltung einer nachhaltigen Datenkultur und Forschungsdateninfrastruktur unerlässlich. In NFDI4Earth bündeln wir daher die Expertise verschiedener Stakeholder in unserer Data in Long-term Storage Measure, bieten mit unserer offenen NFDI4Earth LTA Interessensgruppe ein permanentes multidisziplinäres Forum und stärken den kross-konsortialen Dialog.
In diesem Zusammenhang haben wir eine Umfrage zur Langzeitarchivierung in den Erdsystemwissenschaften in Deutschland mit über 100 Teilnehmenden durchgeführt. Darüber hinaus haben wir drei zentrale Veranstaltungen erfolgreich organisiert, die sich an unterschiedliche Stakeholder-Gruppen richteten: das „Bayern4NFDI – Vernetzungstreffen der NFDI-Beteiligten in Bayern“, das „Werkstattgespräch 2023 zur Archivierung digitaler Geodaten“ und den „NFDI4Earth-Workshop zur Entwicklung von Kriterien für die Bewertung der Archivwürdigkeit von Daten der Bio-/Geowissenschaften“. Mit unseren Aktivitäten zielen wir darauf ab, das Bewusstsein für die Herausforderungen und Anforderungen der digitalen Langzeitarchivierung zu schärfen, zur Entwicklung von Lösungsansätzen und Community-Standards beizutragen sowie Support und FDM-Materialien für eine erfolgreiche Langzeitarchivierung von (Forschungs-)Daten anzubieten.
NFDI4Earth Academy - Training und Vernetzung für die datengetriebenen Erdsystemwissenschaften von morgen
![]()
Wissenschaft lebt von der interdisziplinären Zusammenarbeit, die durch die Fülle von Forschungsdaten und den digitalen Fortschritt vorangetrieben wird. Mit ihrer Academy bietet die NFDI4Earth eine bislang einzigartige Struktur, die Nachwuchswissenschaftler:innen bei der Bewältigung der Komplexität datengetriebener, interdisziplinärer Forschung unterstützt. Spezifisches Data-Science-Training, Peer-Mentoring sowie Zugang und Test der Innovationen und Services von NFDI4Earth sind die wesentlichen Merkmale der Academy.
Der Erfolg der Academy beruht auf ihrer flexiblen Bottom-up Struktur, die von den Academy Fellows und Koordinator:innen gemeinsam gestaltet wird. Dieser Ansatz gewährleistet die bestmögliche Anpassung an die Bedarfe der Fellows. Die Akademie hat bis heute zwei Kohorten mit über 70 Fellows aus 28 Hochschulen und Forschungseinrichtungen in Deutschland erfolgreich unterstützt. Zusätzlich zu den spezifischen Trainingsangeboten für die Fellows intensiviert die Academy die Zusammenarbeit mit der NFDI4Earth-Community und anderen NFDI-Konsortien: Die Academy hat ein offenes Coffee-Lecture-Format etabliert, das sich mit datenwissenschaftlichen und RDM-bezogenen Themen befasst, und organisiert konsortienübergreifende Veranstaltungen, wie den DataXplorer Cross-Community-Hackathon in 2023, zusammen mit NFDI4Biodiversity und NFDI4Microbiota.
Weitere Informationen über unsere Kohorten sind auf der NFDI4Earth Webseite oder in der NFDI4Earth Zenodo Community verfügbar (Erste Kohorte and Zweite Kohorte).
Bereitstellung hochaufgelöster globaler Daten zur Besiedlung als FAIRe Geodaten
![]()
Die rasche Urbanisierung stellt eine zunehmende Herausforderung in verschiedenen Bereichen dar, darunter ökologische, wirtschaftliche und soziale Fragen. Detaillierte Siedlungsdaten sind für verschiedene multidisziplinäre Anwendungsfälle unerlässlich, z. B. für eine genauere Bewertung von Naturgefahren oder eine präzisere Steuerung politischer und wirtschaftlicher Entscheidungen. Das NFDI4Earth-Pilotprojekt „World Settlement Footprint (WSF®)“ liefert hochaufgelöste globale Datensätze zur Besiedlung für die Jahre 2015, 2019 und zur Besiedlungsentwicklung für den Zeitraum 1985-2015.
Die vom DLR-Team „Smart Cities and Spatial Development“ erstellten Daten werden über den EOC Geoservice visualisiert als Karte und zum Download zur Verfügung gestellt. Zudem können sie über einen auf STAC (Spatio-Temporal Asset Catalogue) basierenden Katalog, der den Nutzern eine optimierte Abfrage und Nachnutzung für die Analyse ermöglicht, zugegriffen werden.
Darüber hinaus werden weitere Referenzdatensätze diverser Besiedlungsdaten für Deutschland präsentiert. Die vom Leibniz-Institut für ökologische Raumentwicklung zur Verfügung gestellten Daten werden über den IÖR Monitor zum Download angeboten.
Durch die Anbindung der Datenquellen in den NFDI4Earth Knowledge Hub und dem Angebot als Linked Data, unterstützt NFDI4Earth die Bereitstellung für eine breite Nutzergemeinschaft.
RADAR4Chem - das Repository für Chemiker
![]()
RADAR4Chem basiert auf dem etablierten Forschungsdatenrepository RADAR, das von FIZ Karlsruhe – Leibniz-Institut für Informationsinfrastruktur entwickelt und betrieben wird. Durch persistente Identifikatoren (DOI) und eine Aufbewahrungsfrist von mindestens 25 Jahren bleiben die Forschungsdaten langfristig verfügbar, zitierfähig und auffindbar. Sie werden georedundant in drei Kopien in akademischen Rechenzentren gespeichert. Der Dienst wird in Deutschland nach deutschem Recht betrieben und ist DSGVO-konform. RADAR4Chem kann unabhängig von der institutionellen Zugehörigkeit kostenlos und ohne Vertrag genutzt werden.
NFDI4Chem und DataPLANT: Gemeinsamer Einsatz für einen verbesserten Terminologieservice
![]()
![]()
Das Konsortium NFDI4Chem stellt einen gut aufbereiteten Überblick über die Ontologien in der Chemie [10.1515/pac-2021-2007] bereit. Die Sammlung geht über eine bloße Liste hinaus und beschreibt auch Beziehungen sowie Anwendungsbereiche der Ontologien.
Die Vernetzung innerhalb von NFDI ermöglichte eine Zusammenarbeit mit DataPLANT, dem Konsortium für Pflanzenforschung. Der Bedarf an Ontologien für die Pflanzenforschung, insbesondere zur Erstellung eines institutionellen Datenmanagementplans, führte zur Entwicklung eines umfassenden Überblicks über Ontologien für pflanzenwissenschaftliche Daten. [10.3389/fpls.2023.1279694].
Beide Konsortien bieten nun durchsuchbare Versionen ihrer Sammlungen im NFDI-Terminologiedienst an unter https://terminology.tib.eu/ts/collections. Diese gemeinsame Ressource der NFDI-Konsortien erleichtert den Zugang zu Ontologien und verbessert die FAIRness von Forschungsdaten in der Chemie und Pflanzenbiologie – ein weiterer Schritt zur Verbesserung des Forschungsdatenmanagements in Deutschland.
Forschungsdatenmanagement in der Lehre mit NFDI4Chem
![]()
Eine gute Datenkompetenz ist auch für Studierende wichtig. Die Vermittlung solcher Kompetenz und der Grundlagen des Forschungsdatenmanagements (FDM) ist einfacher, wenn sie mit einem praktischen Ansatz erfolgt. Im Chemiestudium müssen die Studierenden eine Vielzahl von Laborpraktika zu verschiedenen Themen absolvieren. Der Ansatz von NFDI4Chem nutzt die Kombination von chemischen Synthesen mit der Dokumentation im elektronischen Laborjournal (ELN) Chemotion. Dieser Ansatz wird seit dem Wintersemester 2020/21 bereits erfolgreich in einem Pflichtpraktikum für Bachelor-Studenten des 5. Semesters an der RWTH Aachen angewendet. In diesem Praktikum müssen die Studierenden Ferrocen im Labor synthetisieren und die komplette Bearbeitung von Planung über Dokumentation bis zur Auswertung im Chemotion ELN durchführen. Ergänzend gibt es eine theoretische Lerneinheit zu den Grundlagen von FDM, FAIR-Prinzipien, Datenmanagementplänen, Metadaten und InChI & SMILES. Die Studierenden müssen einen Abschlusstest bestehen, um das Praktikum zu bestehen.
Die Integration von FDM und ELN in die curriculare Lehre im Rahmen eines Praktikums hat den großen Vorteil, dass keine Änderungen des Lehrplans erforderlich sind, was nur selten geschieht und oft nicht einfach umzusetzen ist. Auch seitens der Studierenden ist das Feedback positiv: Umfragen zeigen, dass die Studierenden den digitalen Wandel sehr begrüßt haben.
Mehr Informationen über die Umfrage sowie alle Ergebnisse wurden veröffentlicht und sind hier einsehbar: https://pubs.acs.org/doi/10.1021/acs.jchemed.3c00380
